



Robuste, KI-basierte Verhaltensplanung für autonome Systeme
Robuste KI
Projektbeschreibung
Das Deloitte Trustworthy AI Framework beschreibt Kriterien, die KI-Algorithmen erfüllen müssen, um menschliches Vertrauen zu gewinnen. Die Gewährleistung der Vertrauenswürdigkeit ist besonders bei sicherheitskritischen Anwendungen wie dem autonomen Fahren relevant und bleibt eine der offenen Herausforderungen. Wesentliche Aspekte für die Entwicklung vertrauenswürdiger KI-Algorithmen, das supervised oder unsupervised Learning verwenden, wurden im Deloitte Trustworthy AI Framework dargestellt.
Reinforcement Learning ist ein bekanntes Lernparadigma, das in der Robotik und beim autonomen Fahren große Beachtung findet. Es ermöglicht das Erlernen von komplexem Fahrverhalten offline in der Simulation, was den Rechenaufwand der Bewegungsplanungskomponente reduziert. Allerdings lassen sich die Vertrauenswürdigkeitskriterien anderer Lernparadigmen nicht ohne Weiteres auf Anwendungen des Reinforcement Learning übertragen. Im Rahmen des Robuste KI-Projekts hat Deloitte gemeinsam die Anwendbarkeit und Vollständigkeit ihres vertrauenswürdigen KI-Frameworks für das Reinforcement Learning untersucht.
Forschungsbeitrag
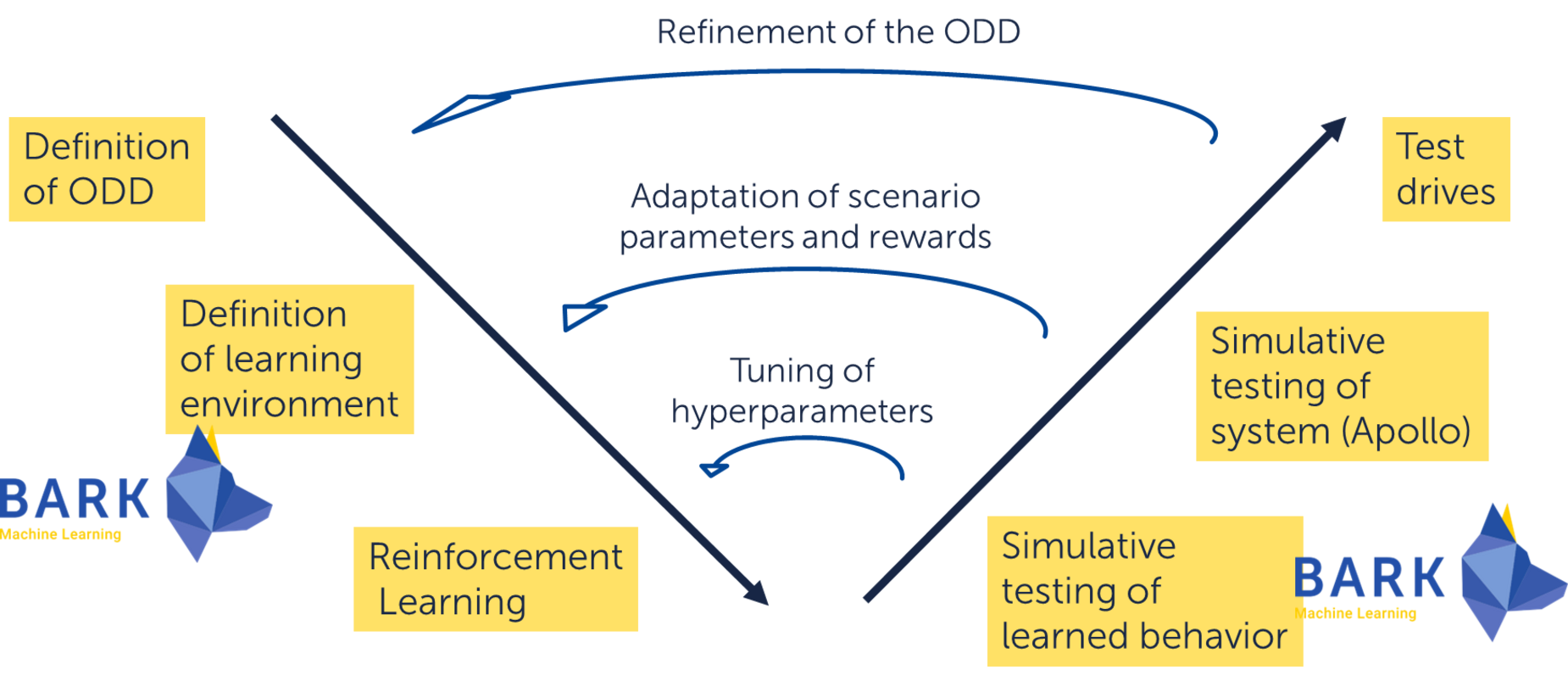
Beim Einsatz in einem realen System sind die idealen Eingabedaten (in der simulierten Umgebung) nicht mehr verfügbar. Daher muss das auf dem Reinforcement Learning basierende Bewegungsplanungsmodul robust gegenüber verminderten Eingabedaten und der Systemleistung sein, wie z. B. Beobachtungsunsicherheit oder zufällige Verzögerungen, aber gleichzeitig eine wertvolle Leistung beibehalten.
Im Rahmen des Projekts Robuste KI wird von fortiss die Gestaltung von Belohnungsfunktionen untersucht, die sich aus den Anforderungen an Vertrauenswürdigkeit und Leistung ableiten. Reward Shaping als Belohnungen des Algorithmus, die ihm helfen, schneller zu konvergieren, wird eingesetzt, um den Lernprozess zu beschleunigen. Im Kontext der datenzentrierten KI hat fortiss sinnvolle Ansätze zur Generierung von Szenarien implementiert, um die ODD-Spezifikation (Operational Design Domain Specification – Betriebsentwurfsbereich-Spezifikation) abzudecken und somit sicherzustellen, dass das System in allen möglichen Szenarien sicher und zuverlässig funktioniert und agiert.
Darüber hinaus wird auch die Möglichkeit untersucht, die Robustheit der KI gegenüber diesen Hindernissen zu verbessern, indem sie bereits bei der Generierung von Trainingsszenarien berücksichtigt werden. Die Ergebnisse fließen in die Open-Source-Software BARK und den Stack für autonomes Fahren Apollo von fortiss ein.
Förderung
Unterstützt durch die Deloitte GmbH
Forschungsdauer
15.01.2022 - 31.12.2023

Wenn Sie dieses Video aktivieren, werden Daten automatisiert an YouTube übertragen.
Kontakt

Weitere Informationen
- Deloitte Whitepaper Towards developing trustworthy behavior for autonomous vehicles using reinforcement learning
- BARK Ein Framework zur Verhaltensmodellierung und -entwicklung autonomer Fahrzeuge
- Apollo Open-Source-Lösung für autonomes Fahren
- aiStudio Deloitte Leverage the full potential of Artificial Intelligence