



Robust, AI-based behaviour planning for autonomous systems
Robust AI
Project description
Deloitte’s trustworthy AI framework describes criteria that AI algorithms must satisfy to gain human trust. Guaranteeing trustworthiness is especially relevant in safety-critical applications such as autonomous driving and remains one of the open challenges. Essential aspects for developing trustworthy AI algorithms using supervised or unsupervised learning paradigms have been structured in Deloitte’s trustworthy AI framework.
Reinforcement learning is a well-known learning paradigm that receives significant attention in robotics and autonomous driving. It enables learning of complex driving behavior offline in simulation, which thus reduces computational demands of the motion planning component. However, the trustworthiness criteria of other learning paradigms cannot be straightforwardly transferred to applications of reinforcement learning. In the context of the Robust AI project, Deloitte collaborates with fortiss to investigate the usability and completeness of their trustworthy AI framework in reinforcement learning.
Research contribution
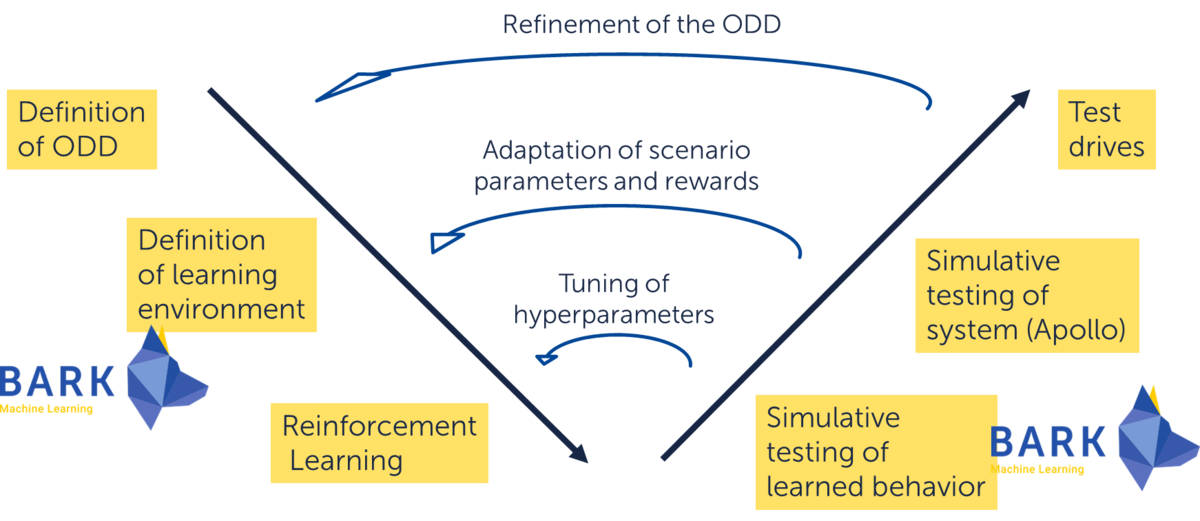
When deploying to a physical system, the ideal input data (in a simulated environment) is no longer available. Therefore, the reinforcement learning-based motion planning module needs to be robust to degraded input data and system performance, such as observation uncertainty and random delays, while still maintaining valuable performance.
The project investigates reward function design derived from the requirements of trustworthiness and performance. Reward shaping as rewards to the algorithm that help it converge faster is used to speed up the learning process. In the context of data-centered AI, fortiss implemented meaningful scenario generation approaches to cover the ODD specification (Operational Design Domain Specification) to ensure that the system functions and acts safely and reliably in all possible scenarios.
In addition, the possibility of improving the robustness of AI against these impediments by already taking them into account during the generation of training scenarios is also being investigated. The results are merged to fortiss open-source software BARK and autonomous driving stack Apollo.
Funding
Supported by Deloitte GmbH
Project duration
15.01.2022 - 31.12.2023

More information
- Deloitte Whitepaper Towards developing trustworthy behavior for autonomous vehicles using reinforcement learning
- BARK A framework for behaviour modelling and development of autonomous vehicles
- Apollo Open source solution for autonomous driving
- aiStudio Deloitte Leverage the full potential of Artificial Intelligence