Das Modell muss Rechenschaft ablegen
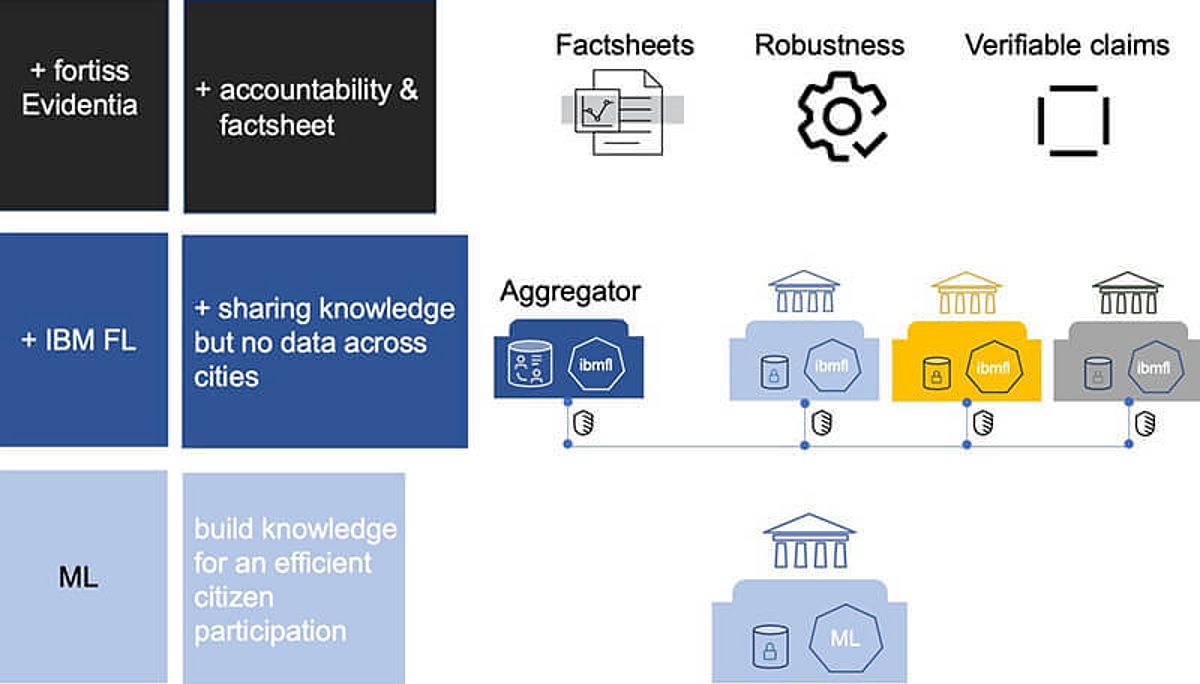
Ein wesentlicher Punkt eines jeden Machine Learning-Modells ist seine Transparenz und Erklärbarkeit. Vor allem im Hinblick auf den Einsatz im behördlichen Rahmen war es wichtig, nachvollziehen und nachweisen zu können, wie das Modell entstanden ist. Die Frage nach der Accountability, also wie genau und wie vertrauenswürdig das Modell ist, wurde von fortiss im nächsten Schritt gemeinsam mit IBM angegangen. Getreu dem Motto „Trust but Verifiy“ wurde ein Accountability Framework entworfen, der die Überprüfung des Modells im Hinblick auf Reproduzierbarkeit und auf eventuelle Fehler, die beim Training unterlaufen sein könnten, ermöglicht. Außerdem musste geklärt werden, ob ein Bias vorliegt (sei es im Hinblick auf das Geschlecht, die Herkunft oder den sozioökonomischen Status der Bürger). Ebenso, ob das Modell fair ist oder in irgendeiner Weise manipuliert wurde.
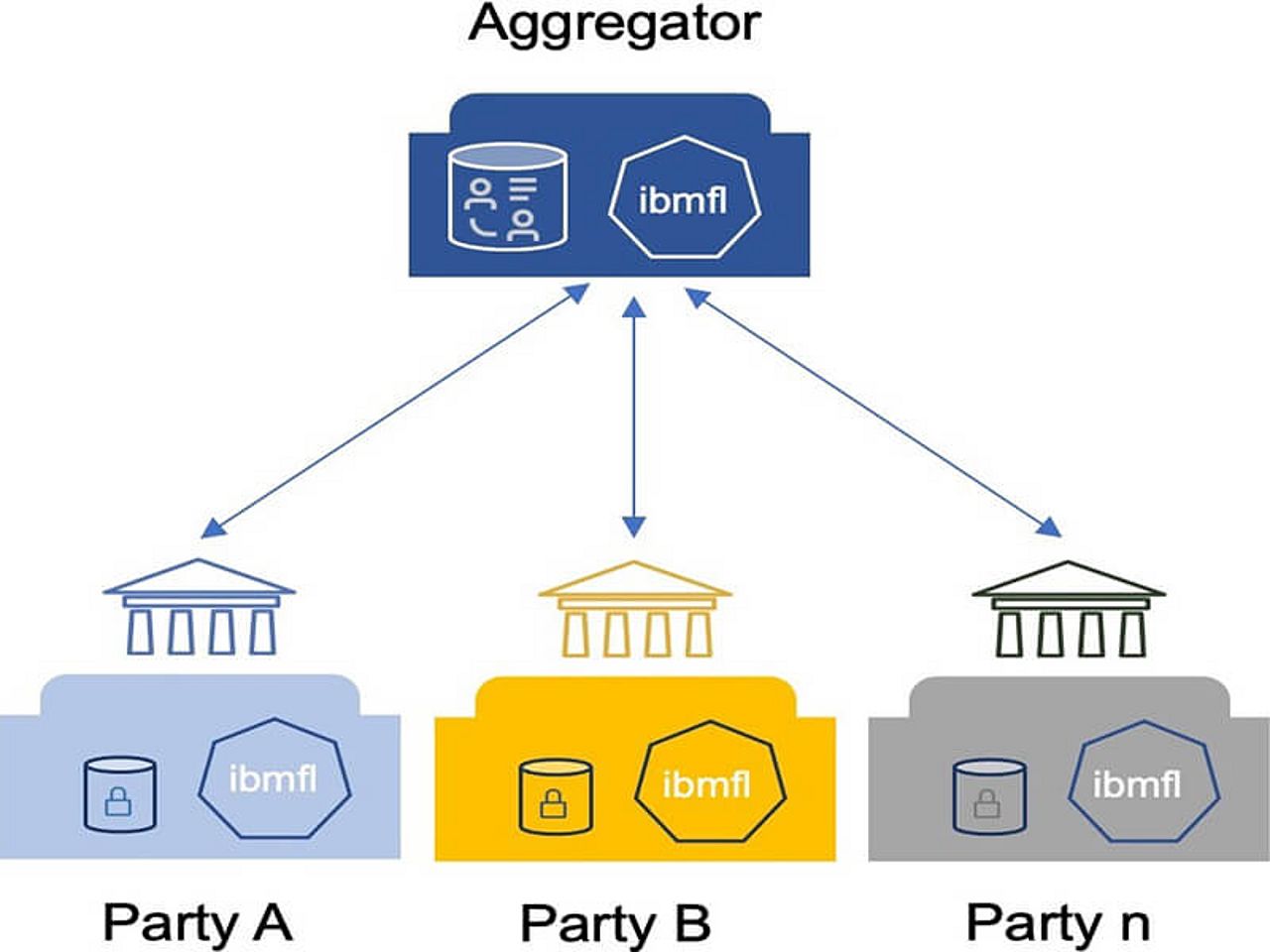
Da bei einem Federated Machine Learning-Modell die Rohdaten nicht vorliegen, ist es schwierig das Modell zu verifizieren. Zwar kann dem System des Federated Learning grundsätzlich vertraut werden. Um aber Rechenschaft über das spezielle Modell ablegen zu können, wurden von IBM und fortiss diverse Behauptungen, sogenannte Claims, mittels der Evidentia-Technologie aufgestellt. Diese beziehen sich auf diverse Punkte des Modells, wie zum Beispiel der Ablauf des Training-Prozesses oder die aufbereiteten Daten. Die Verifizierung dieser Claims ist die Accountability, also die Rechenschaftsprüfung des Modells, die auch Dritten wie beispielsweise Auditoren zugänglich ist.